2021. 11. 4. 21:16ㆍ[5분 SOTA 논문 컨트리뷰션 리뷰]
본 포스팅에서는 ImageNet Classification with Deep ConvolutionalNeural Networks (NIPS 2012) 논문을 간단히 리뷰하였습니다.
모든 그림과 설명은 논문과 Stanford University CS231n Spring 2017 자료를 참고하였습니다.
원문 링크 :
https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-
1. Motivation
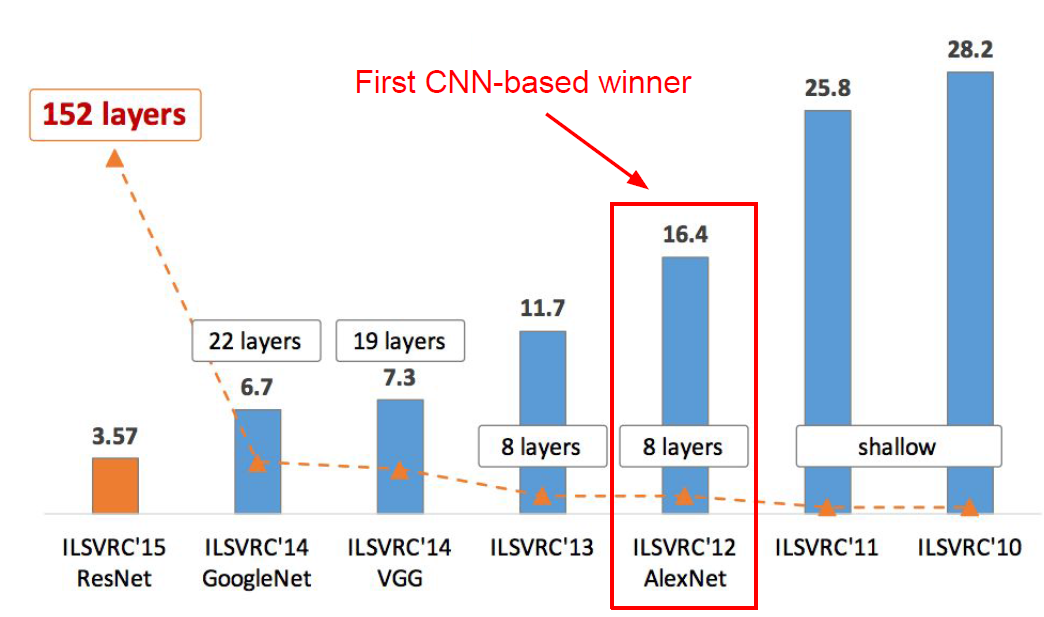
AlexNet 은 기존 SOTA 성능을 달성한 model과 달리 layer의 층을 깊게 하여 ImageNet test(Top-5)에서 기존 정확도를 대폭 증가시킨 model이다.
2. Unique methodology
1) ReLU Nonlinearity
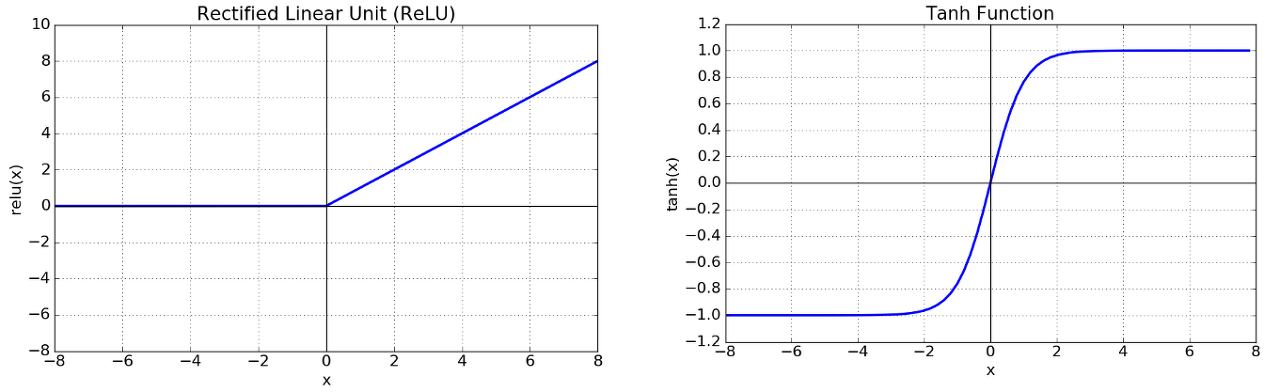
input x의 함수 Neuron의 output을 모델링하는 standard 한 방법으로는
f(x) = tanh(x), f(x) = (1 + e-x)-1 (sigmoid)를 사용하는 것이다.
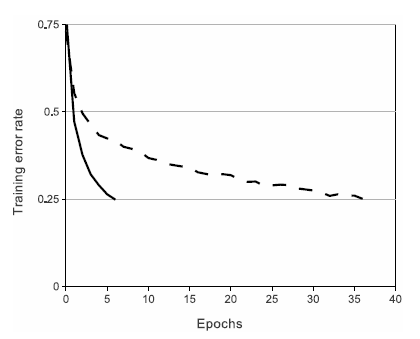
본 논문에서는 기존 tanh, sigmoid 함수와 같이 saturating nonlinearity 방식이 아닌 non-saturating 방식을 이용하는 ReLU 함수를 사용하였다.
ReLU 함수를 사용함으로써 error-rate 가 0.25에 도달하는데 Relu가 tanh에 비해 6배 정도 빠름을 알 수 있다.
2) Training on Multiple GPUs
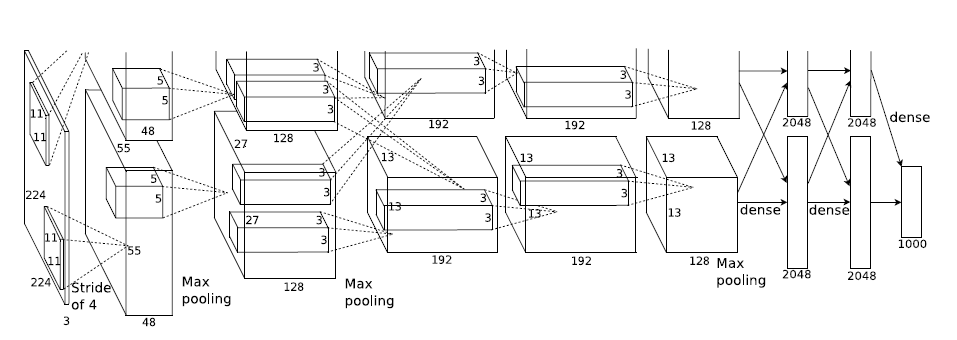
1개의 GTX 580 GPU는 memory가 3GB뿐이기 때문에 모델의 최대 사이즈는 정하는데 한정적이다.
1.2 million 개의 수많은 뉴런들을 1개의 GPU를 사용하여 학습하기 에는 감당이 되지 않아 본 논문에서는 2개의 GPU을 병렬로 구성하였다.
이렇게 병렬적으로 GPU를 구성함으로써 top-1, top-5 error를 각각 1.7%, 1.2% 씩 줄일 수 있었다.
3) Local Response Normalization
본 논문에서는 ReLU 함수를 사용하기 때문에 ReLU 함수의 특징에 따라 양수의 방향으로는 입력값 그대로 사용하게 된다.
이렇게 되면 Conv나 Pooing 시 매우 높은 하나의 픽셀 값이 주변의 픽셀에 영향을 미치게 된다.
이러한 부분을 해결하고자 본 논문에서는 다른 Activation Map의 같은 위치에 있는 픽셀끼리 정규화를 하게 된다.
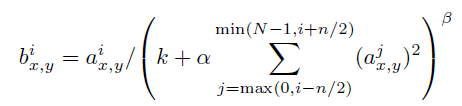
3. Results
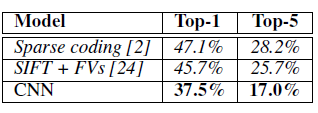
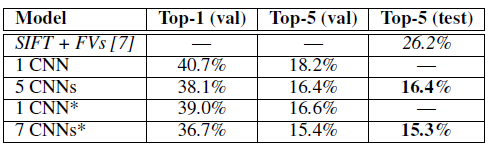
Table 1을 통해 알 수 있는 점은
- ILSVRC-2010 test set 결과, top-1, top-5 error에서 SOTA 성능을 달성하였다.
Table 2을 통해 알 수 있는 점은
- 본 논문에서 제안한 CNN 은 Top-5(val)에서 18.2% 라는 결과를 기록하였다.
- CNN의 층을 깊게 쌓을수록 더 좋은 성능을 보여주고 있다.
- ImageNet 2011 dataset으로 pre-trained 한 model 이 기존 모델보다 더 향상된 성능을 보여주고 있다.
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)
: 대규모 영상에서 영상 분류와 객체 검출 알고리즘을 개발하기 위해서 시작된 대회다.