[5분 SOTA 논문 컨트리뷰션 리뷰 #8] CVPRW 2021, SRFlow-DA: Super-Resolution Using Normalizing Flow with Deep Convolutional Block
본 포스팅에서는 SRFlow-DA: Super-Resolution Using Normalizing Flowwith Deep Convolutional Block (CVPRW 2021) 논문을 간단히 리뷰하였습니다.
그림과 설명은 논문자료를 참고하였습니다.
원문 링크:
https://ieeexplore.ieee.org/document/9523202
SRFlow-DA: Super-Resolution Using Normalizing Flow with Deep Convolutional Block
Multiple high-resolution (HR) images can be generated from a single low-resolution (LR) image, as super-resolution (SR) is an underdetermined problem. Recently, the conditional normalizing flow-based model, SRFlow, shows remarkable performance by learning
ieeexplore.ieee.org
1. Motivation
super-resolution(SR)의 경우 underdetermined problem 이기 때문에 single low-resolution(LR) image를 통해 Multiple high-resolution(HR)을 생성할 수 있다.
최근 conditional normalizing flow을 기반으로 한 SRFlow model 이 HR image의 manifold로부터 latent space
정확하게 mapping 하는 학습을 통해서 주목할만한 성능을 보여주고 있다.
본 논문에서는 기존 SRFlow model의 architecture 보다 더 SR task에 적합한 SRFlow-DA를 제안하였다.
본 논문에서 제시하는 SRFlow-DA model의 경우 기존 SRFlow model의 architecture에서 affine couplings에서 convolutional layer을 증가시켜 receptive field를 확장하였다.
그 결과 SRFlow-DA model 은 기존 SRFlow model 보다 expressive 이 증가하며 또한 X4, X8의 PSNR, LPIPS 측면에서도 더 좋거나 비교할 수 있는 성능을 보여주고 있으며 또한 paremeter 수도 현저히 줄어들었다.
본 논문은 이러한 아이디어를 통하여 NTIRE 2021 Learning the Super-Resolution Space Challenge에서 우수한 성과를 이루 었다.
2. Unique methodology
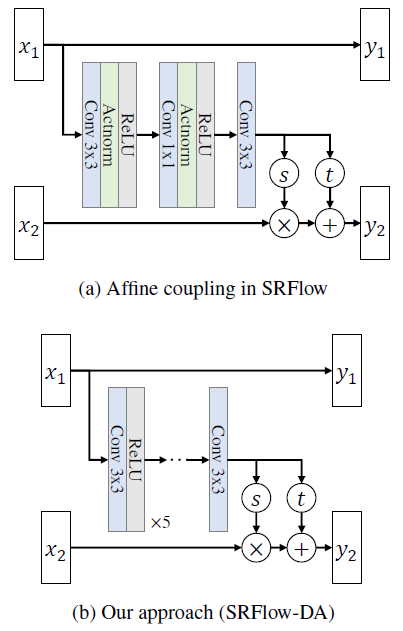
본 논문에서 주장하는 architecture는 Figure 1의 (b)를 보면 (a) 와는 다르게 Actnorm을 제거하게 된 것을 볼 수 있는데 이유는 SR task에 대해서 그렇게 도움이 되지 않는다는 것을 경험적으로 알게 되어 Actnorm layer을 제거하였다.
(하지만 Actnorm layer는 affine layer에서만 제거된 것이며 다른 flow step 에는 여전히 남아 있다.)
기존 SRFlow model 과는 다르게 3x3 convolutional layer을 6개 를 쌓으면서 receptive field의 크기를 기존 5x5에서 13x13으로 증가시켰다.
이렇게 receptive field를 증가시킴으로 써 표현력이 Orginal SRFlow model 보다 더 증가하였다.
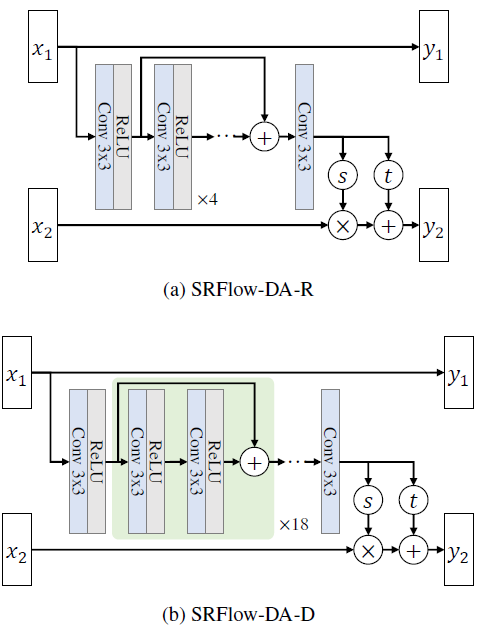
Figure 3 의 그림 중 (a)를 보시면 skip connection을 이용하여 첫 번째 convolutional 값을 마지막 convoultional layer의 입력으로 사용하여 더 많은 feature를 학습할 수 있게 되었다.
Figure 3 의 (b)는 convolutional layer를 증가시면 좋다고 하였으므로 단순히 block을 깊게 한다면 성능 실험을 위한 model의 architecture이다.
3. Results
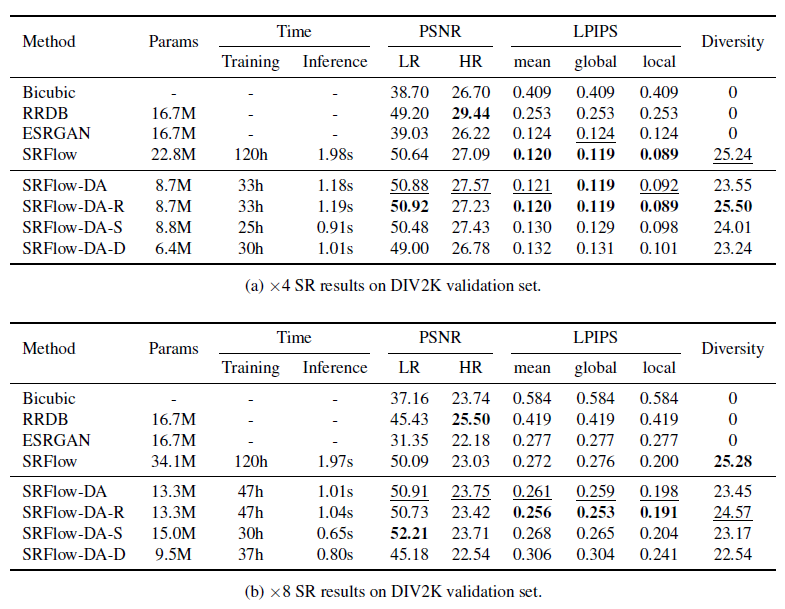



Table 1을 통해 알 수 있는 점은
- 본 논문에서 제시한 SRFlow-DA model 이 기존 SRFlow model 보다 training time이나 PSNR 수치면에서 더 좋은 성능을 보여주는 것을 볼 수 있다.
Figure 2, 4, 5를 통해 알 수 있는 점은
- 본 논문에서 제시한 SRFlow-DA의 Output 이 다른 model 들에 비해 과도한 sharpness artifacts 없이 시각적으로 깨끗한 것을 정성적으로 확인할 수 있다.