[5분 SOTA 논문 컨트리뷰션 리뷰 #2] NeurIPS 2017, Attention Is All You Need
본 포스팅에서는 Attention Is All You Need (NIPS 2017) 논문을 간단히 리뷰하였습니다.
모든 그림과 설명은 논문을 참고하였습니다.
원문 링크 :
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
1. Motivation
기존 기계번역 model 은 encoder, decoder를 포함한 RNN, CNN을 사용하고 있다.
기계번역 task에서 사용된 Seq2Seq model 은 encoder, decoder을 사용하여 입력 시퀀스를 압축하고 출력 시퀀스를 생성하는 모델이다.
하지만 Seq2Seq는 encoder에서 일정 크기로 모든 시퀀스 정보를 압축하여 표현하려고 하기 때문에 정보 손실이 발생하는 단점이 있다.
이러한 단점을 보안하고자 본 논문에서는 Attention Machansim을 기반으로 하며 RNN, CNN을 사용하지 않는 Transformer architecture을 제안하였다.
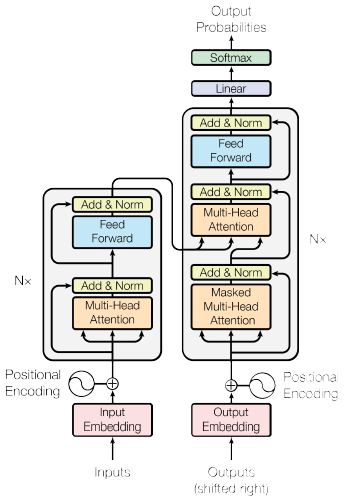
2. Unique methodology
1). Positional Encoding
본 논문에서는 RNN, CNN을 사용하지 않기에 입력값의 위치에 대한 정보를 얻을 수 없다.
이러한 문제를 해결하고자 본 논문에서는 Positional Encoding을 이용하여 위치정보를 받아 오게 된다.
Positional Encoding 은 아래 식과 같이 구할 수 있다.
PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
위 식과 같이 주기 함수를 사용하지 않고 학습된 Positional embedding을 사용해도 된다.
Positional embedding 사용한 결과와 주기 함수를 사용한 결과가 같은 것을 Table 3을 통해 알 수 있다.
하지만 본 논문에서 주기 함수를 사용한 이유는 training 시 사용한 sequnce의 길이보다 긴 sequnce에 대해 더 좋은 성능을 보여주기 때문이다.
2) Attention Mechanism

본 논문에서 는 3가지의 Attention Mechanism을 사용한다.
- Encoder Self Attention : Query = key = value
- Masked Decoder Self-Attention : Query = key = value
- Encoder-Decoder Attention : Query (decoder vector), key = value (encoder vector)
이러한 Attention 방식을 사용하여 Attention scores를 구하게 된다.
Attention scores를 softmax에 넣어 최종적으로 정보를 압축시킨 context vector을 만든다.
3. Results


Table 1
본 논문에서 제시한 model 인 Transformer 이 BLEU, FLOPs 면에서 다른 model 들에 비해 더 좋은 성능을 보여주고 있다.
Table 2
1) 행(B)에서 는 attention key size를 줄이게 되면 model의 성능이 저하되는 것을 알 수 있다.
2) 행(C), (D)에서는 큰 model 일수록 더 좋다는 것을 알 수 있고, dropout을 사용하여 over-fitting을 방지할 수 있다는 것을 알 수 있다.
3) 행(E)에서 학습된 Positional embedding을 주기 함수 대신 사용하였을 때 동일한 값이 나오는 것을 알 수 있다.
BLEU(Bilingual Evaluation Understudy)
:기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법이다.
PPL(Perplexity)
: 펄플렉서티(perplexity)는 언어 모델을 평가하기 위한 내부 평가 지표이다. (헷갈리는 정도)