Figure 1. Different ways of annotating actions while watching a video. (a) Annotating actions in the fully-supervised way. The start and end time of each action instance are required to be annotated. (b) Annotating actions in the weakly-supervised setting. Only action classes are required to be given. (c) Annotating actions in our single-frame supervision. Each action instance should have one timestamp. Note that the time is automatically generated by the annotation tool. Compared to the weakly-supervised annotation, the single-frame annotation requires only a few extra pauses to annotate repeated seen actions in one video.
다양한 supervisied 방식 이 있지만 본 논문 은 새로운 supervision 방식인 single-frame supervision 방식을 이용하고 있습니다.
single-frame supervision 방식의 경우 기존 fully-supervisied 방식에 비해 annotation을 수행하는 데 사용되는 비용과 시간 부분에서 상당히 감소하였으며, 시간 측면에서는 약 6배가량 줄어들었으며 성능 측면에서는 낮은 thresholds 값에서 fully-supervisied 방법보다 조금 차이가 나거나 심지어 더 좋은 성능을 보여주고 있습니다.
2. Unique methodology
Figure 2. Overall training framework of our proposed SF-Net. Given single-frame su- pervision, we employ two novel frame mining strategies to label pseudo action frames and background frames. The detailed architecture of SF-Net is shown on the right. SF-Net consists of a classiffcation module to classify each labeled frame and the whole video, and an actionness module to predict the probability of each frame being action.
본 논문에서 trainingframework는크게 Classification Module, Actionness Module로 구성되어 있으며 성능을 성능을 향상하기 위해 새로운 2가지 mining strategies를 제안하였습니다.
Pseudo action frame
Pseudo background frame
Figure 3. Action frame mining process
Action frame mining을 수행하기 위해 본 논문에서 Fig 3번과 같이 수행을 하였다.
각 action instance의 anchor frame을 설정한다.
anchor frame을 기준으로 하여 최대로 확장할 범위를 제한한다.
확장하던 도중 predicted label과 anchor frame label 이 같고 anchor frame의 action class에 해당하는 classification score 가 높다면 training 시 사용하도록 하는 방식입니다.
두 번째로 background frame mining 같은 경우 background frame 도 model의 성능을 향상하는데 아주 중요한 도움을 주기 때문에 본 논문에서도 background frame을 사용하였다.
Figure 3. The inference framework of SF-Net. The classiffcation module outputs the classi cation score C of each frame for identifying possible target actions in the given video. The action module produces the actionness score determining the possibility of a frame containing target actions. The actionness score together with the classi cation score are used to generate action segment based on the threshold.
또한 각 출력으로 나온 loss를 모두 더하여 같이 학습한다는 특징이 있습니다.
3. Results
Table 1. Comparison between different methods for simulating single-frame supervision on THUMOS14
Table 2. Single-frame annotation differences between different annotators on three datasets. We show the number of action segments annotated by Annotator 1, Annotator 2, Annotator 3, and Annotator 4. In the last column, we report the total number of the ground-truth action segments for each dataset.
Table 3.Segment localization results on ActivityNet1.2 validation set. The AVG indicates the average mAP from IoU 0.5 to 0.95.
Table 4. Segment localization mAP results at different IoU thresholds on three datasets. Weak denotes that only video-level labels are used for training. All action frames are used in the full supervision approach. SF uses extra single frame supervision with frame level classiffcation loss. SFB means that pseudo background frames are added into the training, while the SFBA adopts the actionness module, and the SFBAE indicates the action frame mining strategy added in the model. For models trained on single-frame annotations, we report mean and standard deviation results of five runs. AVG is the average mAP from IoU 0.1 to 0.7.
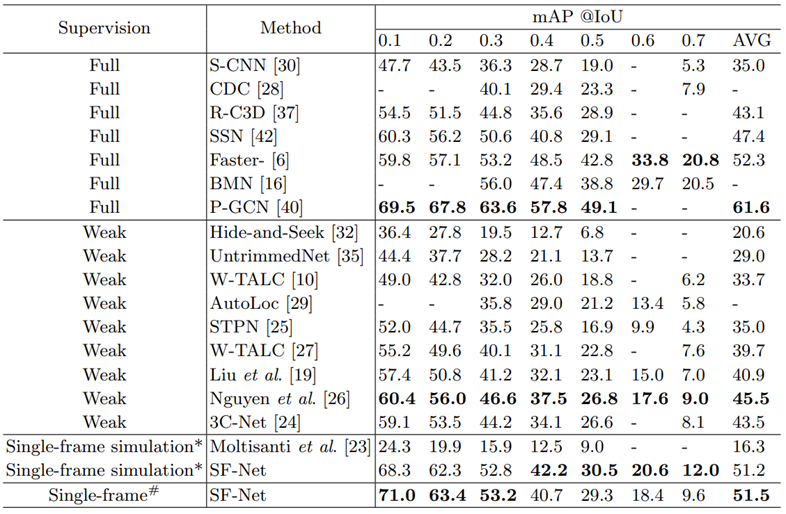
Table 5.Segment localization results on THUMOS14 dataset. The mAP values at different IoU thresholds are reported, and the column AVG indicates the average mAP at IoU thresholds from 0.1 to 0.5. * denotes the single-frame labels are simulated based on the ground-truth annotations. # denotes single-frame labels are manually annotated by human annotators.
Table 1, 2를 통해 알 수 있는 점은
annotation 방법에 따른 성능 평가 결과를 볼 수 있다. 본 논문에서는 manually 하게 annotation 하는 방식을 선택하였으며 table 1 속에서도 가장 좋은 성능을 보여주고 있습니다.
또한 Table 2 경우 본 논문에서는 4 명의 annotator 가 manually 하게 annotation을 진행하기 때문에 annotator 간에 차이를 보여주고 있습니다.
Table 3을 통해 알 수 있는 점은
ActivityNet 1.2 dataset의 경우 dataset의 양이 많기 때문에 그것을 manually 하게 annotation 하기에는 무리가 있기 때문에 random 하게 annotation을 진행하였으며, 비록 본 논문에서 제시한 manually 한 방식은 아닐지라도 우수한 성능을 보여주고 있습니다.